Case
Sparkify
Cloud computing met behulp van Amazon Web

Blog: Klantenverloop voorspellen
Klant
Sparkify
Periode
2023
Resultaten
Overzicht van de Sparkify-data
Sparkify is een fictieve muziekstreamingservice. De dataset lijkt op de gegevens die worden verzameld door platforms als Spotify en Pandora.
Miljoenen gebruikers spelen hun favoriete nummers dagelijks af via muziekstreamingservices, hetzij via een gratis abonnement dat advertenties afspeelt, of door een premium abonnementsmodel te gebruiken, dat extra functionaliteiten biedt en doorgaans reclamevrij is.
Gebruikers kunnen hun abonnement op elk moment upgraden of downgraden, maar ze kunnen het ook helemaal opzeggen. Ik zal me concentreren op het voorspellen van het verloop waarbij gebruikers hun abonnement volledig hebben opgezegd (gebruikers die zijn gestopt met het gebruik van de service van Sparkify en niet alleen hun abonnement hebben gedowngraded).
Cloud computing met behulp van Amazon Web Service EMR (AWS)
Amazon EMR (Elastic MapReduce) is een big data-platform in de cloud voor het verwerken van enorme hoeveelheden data met behulp van open source-tools zoals Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi en Presto. Met EMR kun je analyses op petabyteschaal uitvoeren tegen minder dan de helft van de kosten van traditionele on-premise oplossingen en meer dan 3x sneller dan standaard Apache Spark.
Om modellen op zo’n grote dataset te kunnen draaien, heb ik de EMR-service van AWS gebruikt. Ik heb besloten om krachtigere machines met meer cores en geheugen voor deze klus te gebruiken dan aanbevolen, zij het tegen een hogere prijs. Je moet wel echt rekening houden met de kosten om het aantal machines voor je cluster te kiezen.
Ik had een cluster van 3 ‘nodes’.
Dit is de configuratie van mijn cluster:
Master: 1x r5.12xlarge (48 vCore, 384 GiB-geheugen, alleen EBS-opslag)
Nodes: 2x r5.12xlarge (48 vCore, 384 GiB-geheugen, alleen EBS-opslag)
Voor mijn aangepaste configuratie van de spark-context, raadpleeg mijn github met de Jupyter-notebookcode. Het lijkt erop dat de standaardinstellingen van Amazon EMR voor maximale resourcetoewijzing niet de volledige capaciteit van het cluster gebruiken. Ik heb een aantal best practices geïmplementeerd rond het opzetten van een cluster in EMR. Zie hier.
Met deze setup kon ik al mijn modellen binnen een uur laten draaien.
Data Understanding
Allereerst werd er geen documentatie voor de gegevens verstrekt, daarom heb ik de data moeten verkennen om de datastructuur en de relatie tussen variabelen te begrijpen.
De dataset is een json-bestand en bestaat uit 26,259,199 gebruiksersinteracties van 22,278 gebruikers van Sparkify. De gegevens zijn verzameld van 10-1-2018 tot 12-1-2018.
Van deze gebruikersinteracties zijn 778,479 datapunten afkomstig van gebruikers die niet op het platform zijn geregistreerd, als zodanig worden deze gebruikers uitgefilterd. Ik kon deze identificeren aan de hand van lege namen en een ontbrekend registratiedatumveld.
In tegenstelling tot mijn verwachtingen, is het verloop-percentage 22,45% in deze dataset, wat betekent dat ongeveer elke vijfde gebruiker in de dataset een churner is. Churn-voorspelling omvat meestal ongebalanceerde klassen, waarbij slechts een klein percentage gebruikers churners zijn, dus theoretisch zijn in dit geval over- of onderbemonsteringstechnieken, gestratificeerde train- en testsplits en gestratificeerde k-fold cross validation niet zo nodig en volstaat het met een random train en test split toch een behoorlijk resultaat te verwachten.
De loggegevens hebben een aantal onregelmatigheden. Behalve de gebruikers die niet geregistreerd zijn, waren er ook enkele ontbrekende gebruikers-ID’s die verwijderd moesten worden.
Ik heb ook een nieuw veld gemaakt met de naam Staat, dat is afgeleid van het veld Locatie, wat handig kan zijn voor de analyse. We kunnen dan churn-aantallen vergelijken tussen staten en zien of bepaalde staten meer verloop hebben dan andere staten.
Ter illustratie, de loggegevens worden weergegeven in het volgende formaat:
Row(artist=’Popol Vuh’, auth=’Logged In’, firstName=’Shlok’, gender=’M’, itemInSession=278, lastName=’Johnson’, length=524.32934, level=’paid’, location=’Dallas-Fort Worth-Arlington, TX’, method=’PUT’, page=’NextSong’, registration=1533734541000, sessionId=22683, song=’Ich mache einen Spiegel — Dream Part 4′, status=200, ts=1538352001000, userAgent=’”Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.143 Safari/537.36″’, userId=’1749042′)
Met uitzondering van de ID’s voor de gebruiker, de naam en de agent die door de gebruiker worden gebruikt bij het gebruik van Sparkify, zijn er enkele interessante variabelen die het onderzoeken waard lijken om inzicht te krijgen in wat een churner onderscheidt van een niet-churner.
Data Exploration
Er zijn veel verschillende manieren om klantenverloop te voorspellen, afhankelijk van de context. Een specifiek concept van voorspellende variabelen is het concept van RFM: recency (recentheid), frequency (frequentie) en monetary value (monetaire waarde).
Recency staat voor hoe recent een gebruiker een dienst heeft gebruikt, dit kan worden gemeten in tijdseenheden in een bepaalde tijdsperiode, meestal vanaf de laatste sessie of vanaf een bepaald tijdstip. Actieve gebruikers gebruiken een dienst vaker en hebben daardoor minder tijd tussen sessies en hebben een lagere neiging tot verloop.
Frequency staat voor hoe vaak een gebruiker een service gebruikt in een bepaald tijdsbestek. Hoe vaker een gebruiker de service gebruikt, hoe kleiner de kans dat hij / zij dus churnt.
Monetary value staat voor de hoeveelheid geld die door een gebruiker wordt uitgegeven, hoe meer er wordt uitgegeven, hoe meer een gebruiker zich inzet voor de service en er dus in theorie minder kans is op churn.
Ik zal het hierboven genoemde RFM concept op een unieke manier implementeren voor Sparkify-gebruikers, hoewel het laatste concept van geldwaarde in deze situatie niet direct toepasbaar is.
We kunnen dit geldwaarde concept echter vervangen door variabelen zoals het aantal verschillende paginabezoeken, het gemiddelde aantal sessies in een tijdsperiode en de sessieduur, die in deze context enigszins vervangers zijn voor geldwaarde.
Paginabezoeken
Laten we eerst eens kijken hoe paginabezoeken en hun frequentie verschillen tussen churners en niet-churners. De gebruikte diagramtypen variëren tussen gewone histogrammen of Seaborn’s distplot (kerneldichtheidsverdelingsplot) om de verdeling van gegevens tussen churners en niet-churners te tonen. De onderstaande grafiek illustreert wat de frequentie is van verschillende paginabezoeken door churners en niet-churners.
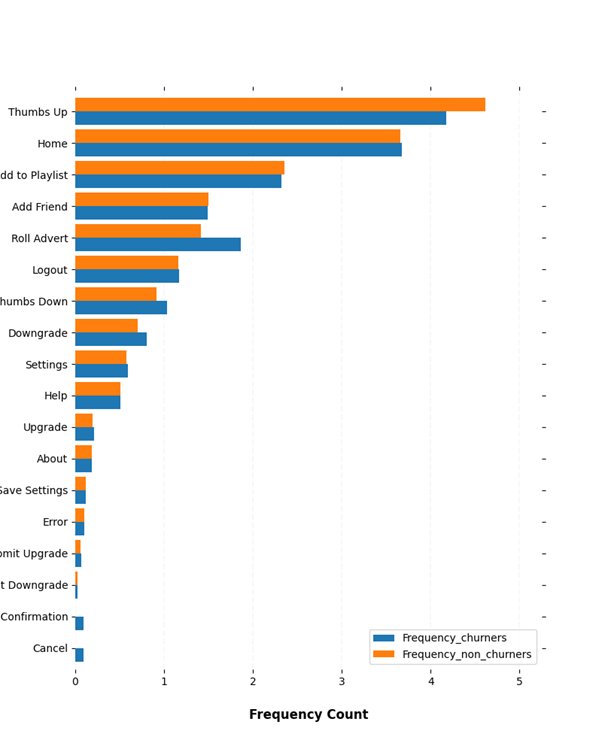
Er lijken geen grote verschillen te zijn in de verdeling van paginabezoeken tussen churners en niet-churners, hoewel het lijkt alsof niet-churners meer ‘Thumbs up’ geven voor de nummers die ze leuk vinden in vergelijking met niet-churners. Het lijkt er ook op dat churners meer advertenties ontvangen (‘Roll-advertentie’) in vergelijking met niet-churners, wat logisch is omdat er meer churners in het gratis abonnement zitten dan in het betaalde abonnement.
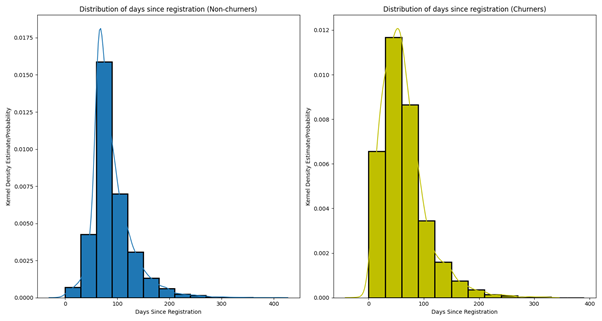
Dagen sinds registratie
Laten we eens kijken naar het aantal dagen dat een gebruiker gebruik maakt van een service. Hypothetisch gezien geldt dat hoe langer een gebruiker een dienst gebruikt, hoe kleiner de kans dat hij/zij zal stoppen met de service.
Aantal sessies (dagelijks / maandelijks)
Laten we eens kijken naar het gemiddelde aantal sessies op dag- en maandniveau.

Op een maandelijks niveau lijkt het gemiddelde aantal sessies gelijk verdeeld te zijn over churners en niet-churners. Op dagniveau is er echter een verschil te vinden tussen churners en niet-churners, het lijkt erop dat churners relatief gezien meer aantal sessies hebben op dagelijks niveau in vergelijking met niet-churners.
Gemiddelde dagelijkse / maandelijkse sessieduur
Je hebt deze waarschijnlijk al aan zien komen, als we het aantal sessies per tijdsperiode weten, kunnen we net zo goed de sessieduur tussen churners en niet-churners vergelijken, aangezien we de tijd van elke interactie hebben.
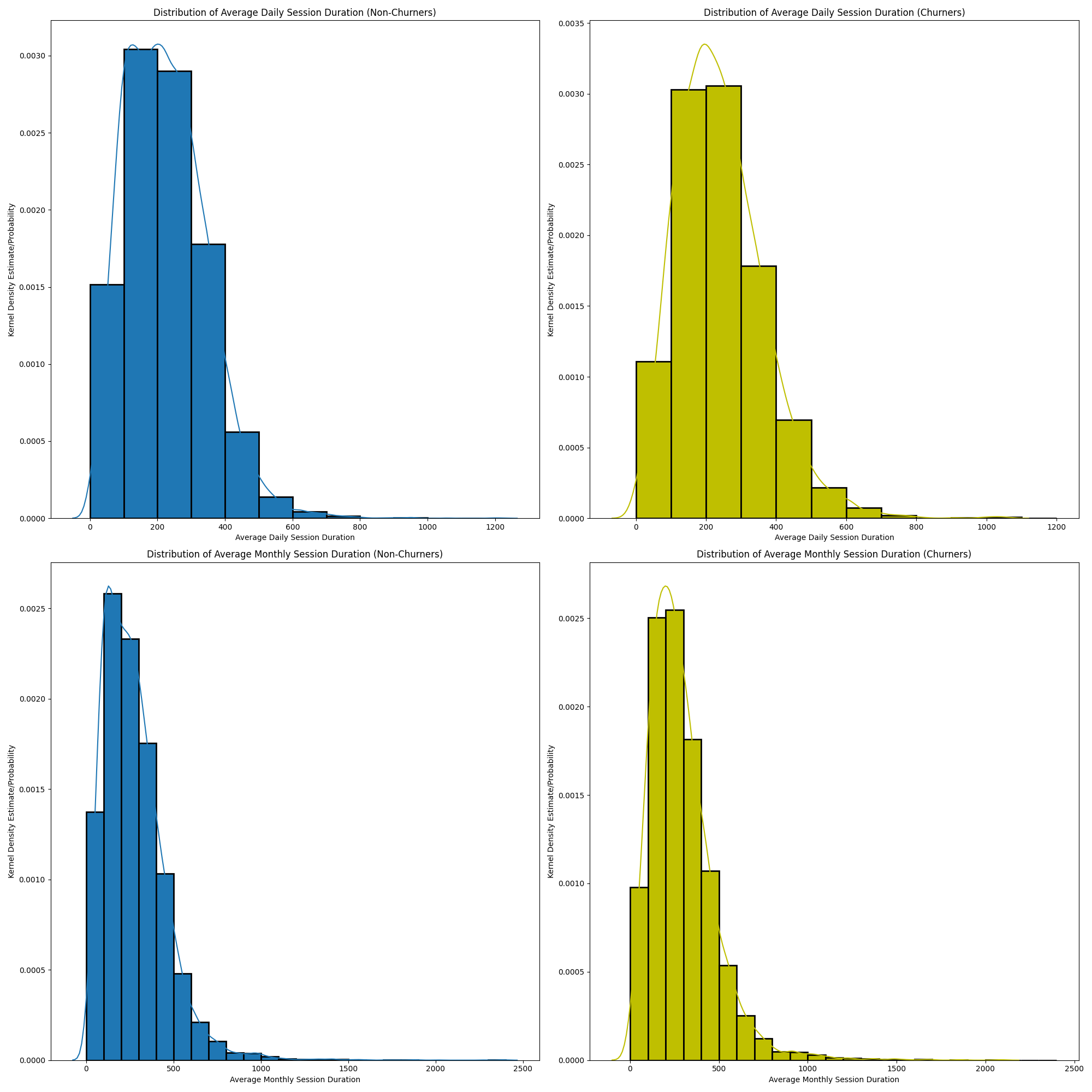
De distributies volgen een soortgelijk patroon in het geval van sessieduur.
Recentheid
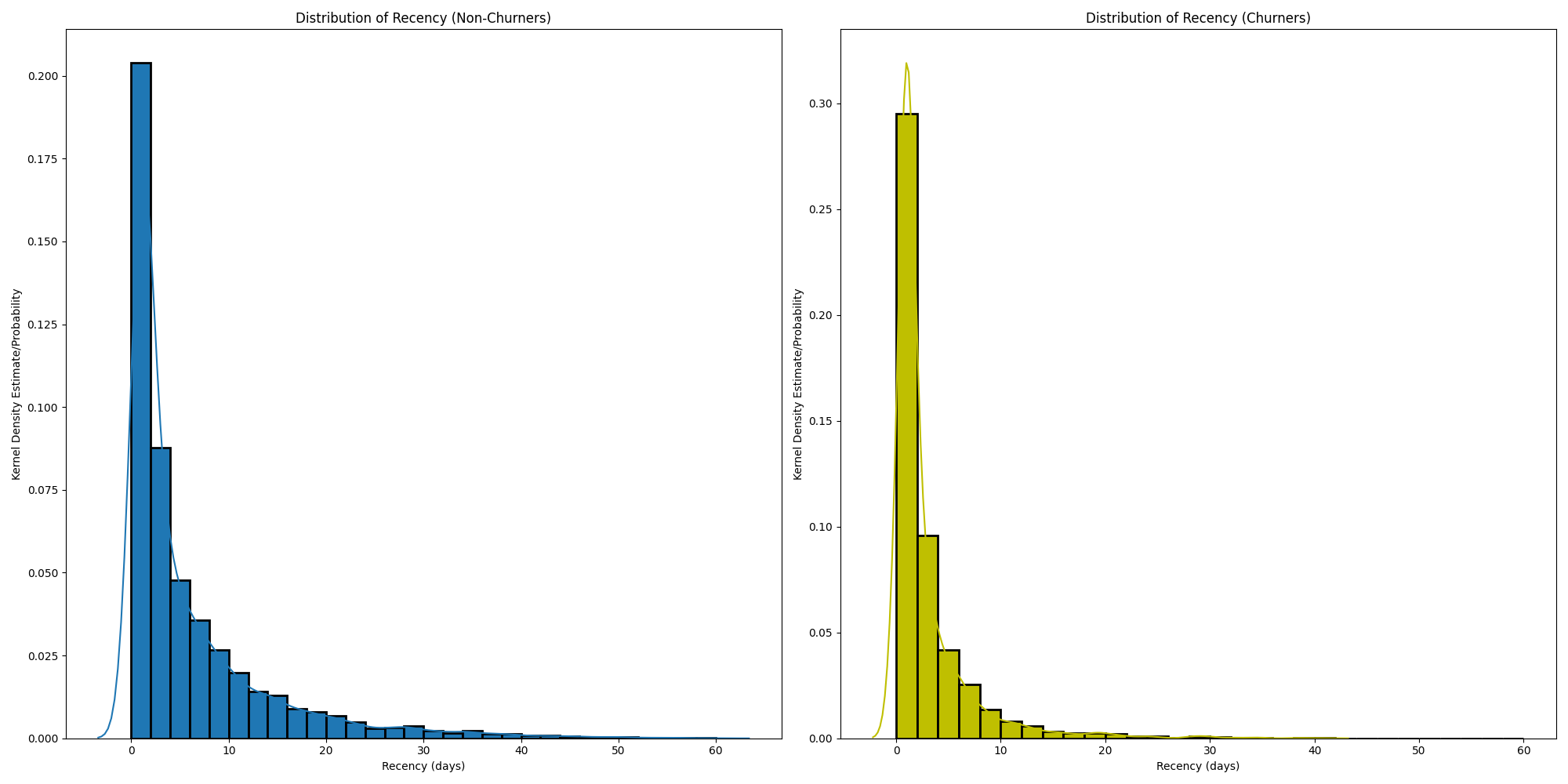
Het lijkt erop dat niet-churners net iets minder dagen hebben zitten tussen de laatste sessie en de sessie ervoor in vergelijking met churners, vooral door naar de derde balk te kijken, waar de relatieve waarschijnlijkheid voor dit aantal dagen hoger is dan die van churners. Echter, het verschil is niet groot.
Aantal unieke artiesten dat is beluisterd
Deze lijkt ook een goede voorspeller, ervan uitgaande dat churners over het algemeen minder muziek luisteren, maar mogelijk ook naar minder artiesten luisteren in vergelijking met niet-churners, omdat ze andere platforms kunnen gebruiken voor andere artiesten waar ze naar luisteren (kan te maken hebben met licenties) of ze luisteren over het algemeen niet zo vaak naar muziek.

Het lijkt erop dat de verdeling van waarden een soortgelijk scheef patroon volgt, maar de relatieve kans dat een churner in de eerste klasse van beluisterde artiesten valt, lijkt hoger (0,0014) in vergelijking met dezelfde klasse voor niet-churners (ongeveer 0,0013), maar dit is niet heel relevant.
Aantal verschillende nummers beluisterd
Hetzelfde als hierboven, maar dan kijkend naar het aantal verschillende nummers waar naar geluisterd is.
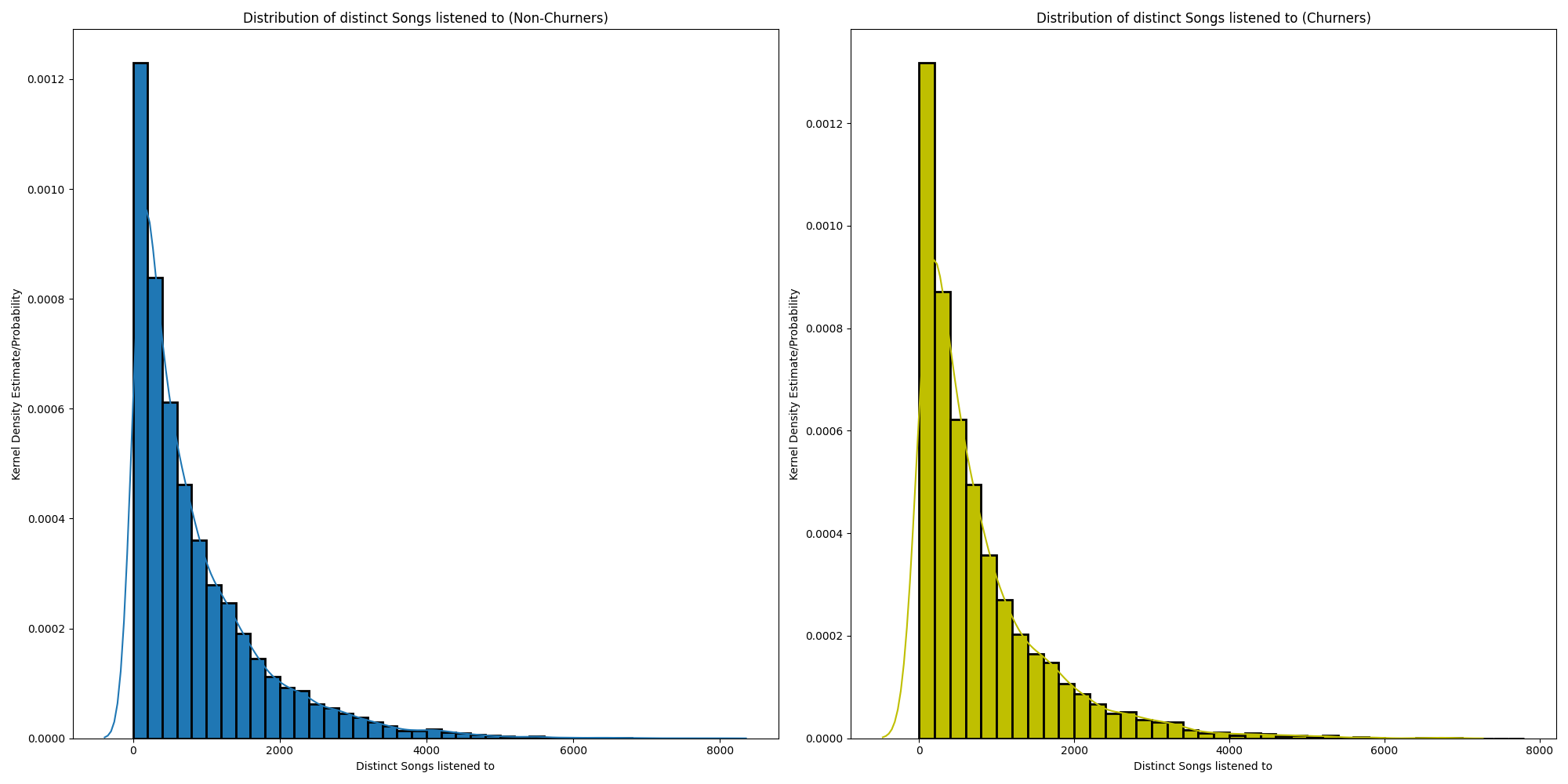
Het lijkt erop dat churners naar iets minder unieke nummers luisteren in vergelijking met niet-churners (vooral als je kijkt naar de eerste kolom)
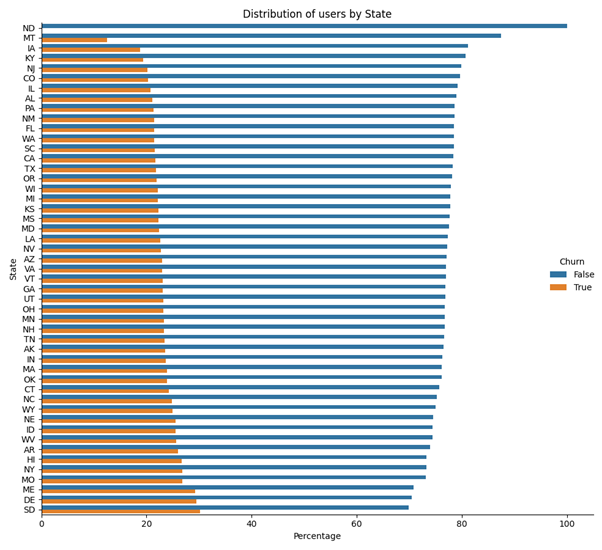
Churn per staat
Laten we eens kijken naar de verschillen tussen (Amerikaanse) staten, is er een significant verschil tussen churners en niet-churners met betrekking tot hun locatie? Montana kent relatief weinig churners (ongeveer 20%) ten opzichte van bijvoorbeeld South Dakota (30%).
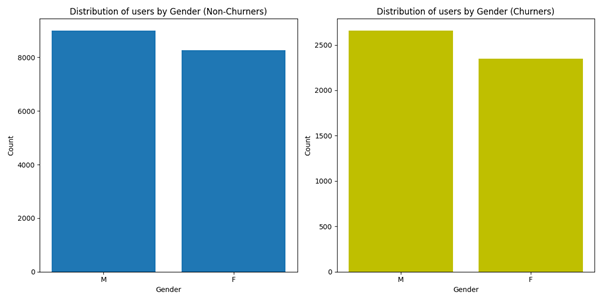
Geslacht en churn
Ik aarzelde om dit veld op te nemen, omdat ik verwachtte dat het verloop gelijk zou zijn tussen mannen en vrouwen. Uit de onderstaande grafiek blijkt echter dat er meer mannelijke (M) gebruikers dan vrouwelijke (F) gebruikers van het platform zijn, zo ook zijn er wat meer mannelijke churners dan vrouwen.
Feature Engineering
Ik heb de variabelen voor het machine learning-model ontwikkeld volgens de volgende stappen:
- Identificeren van variabelen door de bovenstaande gegevens per gebruiker te verzamelen. Ik heb functies gedefinieerd om gegevens te aggregeren en deze berekende velden terug te voegen aan het hoofd-dataframe.
- Door de binaire responsvariabele te definiëren, krijgen verlopen gebruikers een ‘1’-label, niet-churners een ‘0’-label. Zoals in het begin werd gezegd, wordt churn gedefinieerd als gebruikers die hun abonnement volledig opzeggen, ongeacht of ze een betaald abonnement hebben of niet.
- Het transformeren van de originele dataset (één rij per gebruikersinteractie) naar een dataset met statistieken op gebruikersniveau (één rij per gebruiker).
Modelleren
In de modelleringsfase ging ik verder met het volgende:
- Definiëren van machine learning-pipelines met Spark MLlib voor elk model: het indexeren van tekstvariabelen (‘geslacht’, ‘staat’), one hot-codering (‘niveau’, ‘geslacht’, ‘staat’), MinMax-standaardisatie van de numerieke variabelen (vanwege sterk scheve gegevens), feature-assemblage en een binaire classificator (logistische regressie, random forest en gradiënt-boosted trees-model)
- Splitsen van de data in een training en test-set met behulp van een 80/20 train/test-split
- Trainen van het model en afstemming met behulp van grid-search met drievoudige cross-validation op de train data.
- Voor logistieke regressie heb ik de volgende hyperparameters gebruikt: regularisatieparameter: 0, 0,1, maximale iteraties: 10
- Voor Random Forest heb ik de volgende hyperparameters gebruikt: aantal bomen: 10, 20; maximale boomdiepte: 10, 20
- Voor Gradient Boosted Trees heb ik de volgende hyperparameters gebruikt: maximale iteraties: 5, 10; maximale boomdiepte: 5, 10, 20.
- Analyseren van de prestaties van elk model in cross-validation met behulp van F1 en het testen van het model op de test-set (met behulp van Accuracy (nauwkeurigheid), F1-score en AUC).
Evaluatie criteria
Aangezien churn-voorspelling een classificatieprobleem is met doorgaans sterk ongebalanceerde klassen, is het ook nodig om modellen niet alleen te evalueren op basis van voorspellings nauwkeurigheid (Accuracy), maar ook op basis van Recall en Precision en AUC (Area-under-curve).
Recall en Precision kunnen worden geëvalueerd met behulp van de F1-score, die deze twee statistieken combineert tot een enkele metriek door het harmonische gemiddelde te nemen.
Resultaten
De resultaten worden per model weergegeven:
Logistieke regressie
De nauwkeurigheid op de test-set is 83,33%
De F1-score op de test-set is 80,37%
De areaUnderROC (AUC) op de test-set is 81,02%
De hyperparameters van het beste model zijn:
maximale iteraties: 10
regularisatieparameter: 0
Random Forest
De nauwkeurigheid op de test-set is 94,49%
De F1-score op de test-set is 83,74%
De areaUnderROC (AUC) op de test-set is 84,44%
De hyperparameters van het beste model zijn:
aantal bomen: 20
maximale diepte: 20
Gradient Boosted Trees
De nauwkeurigheid op de test-set is 85,41%
De F1-score op de test-set is 82,73%
De areaUnderROC (AUC) op de test-set is 82,58%
De hyperparameters van het beste model zijn:
maximale iteraties: 10
maximale diepte: 5
Conclusie
Door de goede prestaties van de drie modellen zijn we erin geslaagd een voorspellingsmodel te ontwikkelen dat churners nauwkeurig kan identificeren op basis van loggegevens met de interacties en gebruikspatronen van de gebruiker.
Het best presterende model was Random Forest, dat behoorlijk goede voorspellingsresultaten behaalde op de testset, met een nauwkeurigheid van 94,49%, en ook hoogwaardige voorspellingsstatistieken voor de verschillende klassen (churners en niet-churners).
Dat wil zeggen dat, kijkend naar de AUC-score van het beste model, in ongeveer 84,4% van de gevallen een willekeurige positieve klasse (churner) hoger rangschikt dan een willekeurige negatieve klasse (niet-churner). Kijkend naar de F1-score, wat het gewogen gemiddelde is van Recall (het correct identificeren van churners gegeven dat het churners zijn) en Precision (het aantal correct geïdentificeerde churners van alle gevallen die geclassificeerd zijn als churner-zijnde door het model), zien we ook een hoge score van 83,74%.
Het getrainde model kan worden ingezet om Sparkify te helpen bij het identificeren van huidige gebruikers die risico lopen op verloop, en om het voor Sparkify gemakkelijker te maken om een individuele korting te bewerkstelligen voor deze churners die een verhoogd risico op verloop hebben.
Als ik terugkijk op het werk, kan ik zeggen dat het meest uitdagende deel was om met goede variabelen te komen, maar het is ook het leukste deel. In deze situatie waarin er geen documentatie over de gegevens wordt gegeven, was het leuk om creatief te worden en belangrijke functies te zoeken die nuttig kunnen zijn om het verloop te voorspellen.
Mogelijke verbeteringen
Er zijn verschillende verbeteringen mogelijk:
- Misschien zou stratified cross-validation met een gestratificeerde train- en teststeekproef kunnen worden geïmplementeerd om te zien of dit de prestaties van het model zal verbeteren, hoewel in dit geval, waar klassen niet zo onevenwichtig zijn, niet zo zeker is of het de voorspellingsnauwkeurigheid aanzienlijk zal verbeteren.
- Misschien kunnen andere gebruikersgegevens (indien beschikbaar) worden gebruikt, gegevens over het luistergedrag van gebruikers, zoals nummers die worden overgeslagen, naar welke afspeellijsten een gebruiker luistert, hoeveel persoonlijke afspeellijsten door de gebruiker zijn aangemaakt/verwijderd, enz.
- Uitgebreidere hyperparameter grid search, hoewel de complexiteit en rekentijd van het model dramatisch kunnen toenemen, maar het moet gezegd worden dat met de huidige hyperparameters de modellen al behoorlijk goede prestaties leveren en dat extra afstemming de resultaten niet noodzakelijkerwijs verbetert. Misschien zou in het geval van Random Forest de maximale boomdiepte (tree-depth) enigszins kunnen worden verhoogd, aangezien op te merken valt dat met andere parameters die constant blijven, een hogere boomdiepte lijkt te resulteren in een hogere F1-score.
Raadpleeg mijn github-repo voor de volledige code.

Zij vertrouwen op onze expertise
We werken met gevestigde namen en groeiende bedrijven in alle sectoren. Want data is overal.











Ontdek meer cases
Hoe we organisaties helpen betere keuzes maken met hun data.


.png)



Copyright ©2026 Always Be Learning B.V.